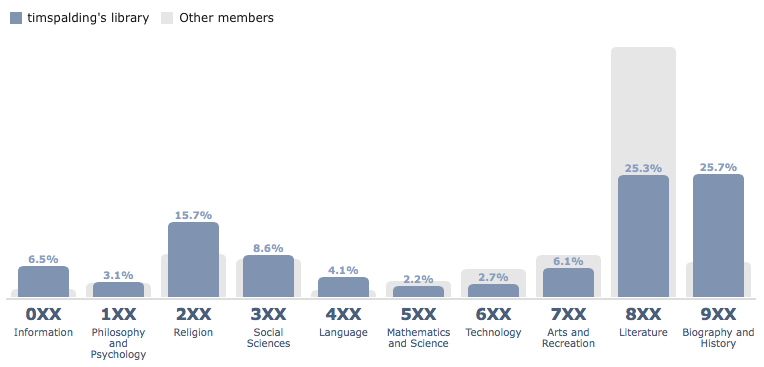
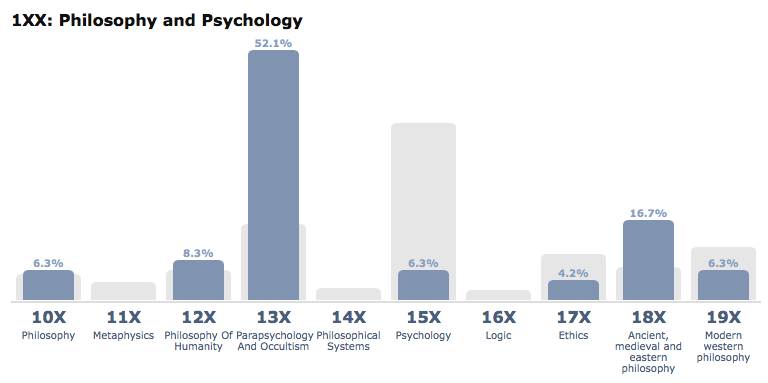
Today is LibraryThing’s 12th anniversary! To celebrate, we held a cataloging race with our three key cataloging methods going head-to-head-to-head:
Today is LibraryThing’s 12th anniversary! To celebrate, we held a cataloging race with our three key cataloging methods going head-to-head-to-head:
- Mobile app
- CueCat barcode scanner
- The human hand (via the Add Books page)
See the video to see who won (besides office assistant/dog Gunner, obviously).
Over the years, LibraryThing has evolved to focus on cataloging efficiency, to benefit data-lovers and libraries (hey there, TinyCat) everywhere. Today, we’ve got 12 years and 117 MILLION books’ worth of cataloging under our belt.
However you catalog, we’re happy you’re here with us. We’d like to send a huge “Thank you!” to all our members. You help make LT what it is—a great place to be.
Grab your party hat and come share in the celebration on Talk.







 Publishers do things country-by-country. This month we have publishers who can send books to the US, Canada, the UK, Israel, Australia, France, and many more. Make sure to check the flags by each book to see if it can be sent to your country.
Publishers do things country-by-country. This month we have publishers who can send books to the US, Canada, the UK, Israel, Australia, France, and many more. Make sure to check the flags by each book to see if it can be sent to your country.