As most of you know, back in July the Open Shelves Classification was conceived as a free, crowdsourced alternative to the Dewey Decimal System. The Group has been very active during initial development, and the top levels are being heatedly debated.
David, Tim and I held an OSC open-discussion at the American Library Association (ALA) conference in Denver. A great group of people participated in a lively debate about the project.
To summarize:
There was some room confusion with the Marriott and, unfortunately, many people left before it was all figured out.
10 people attended: Tim, Laena, David, a mix of public librarians, academic librarians, and one interested non-librarian. The librarians were catalogers, reference librarians, and one library director.
Comments during the meeting included:
The random works feature is not that useful because half of all the works are fiction and fiction is not broken out at the top level.
If a public library may reasonably want to aggregate at a certain level (e.g. fiction or science) then it should exist as a top level. No one aggregates at non-fiction, hence it is not useful.
Working on the second level for fiction should happen sooner rather than later.
Children’s books are a challenge.
Perhaps using an audience facet would help (for example, CH, YA)?
- Yes, but the topics of some books are hard to determine. Should they be put in fiction? If so, a scope note is needed.
- Speaking of which, there is no good way of dealing with series when written by separate authors, like Spongebob Books.
How should series be handled in a classification?
The Darien library is reorganizing their collection, particularly children’s books, in interesting ways (here, you can listen to Gretchen Hams tell you all about it).
For OSC to be successful, it must be easy to implement for public libraries.
It must be inexpensive to go from DDC-OSC.
A crosswalk is essential!
- There needs to be a way to determine how much space is needed ahead of time to move the books around.
- It must be easy to print labels.
- Backstage Library Works was a company that moved Duke University Libraries from DDC to LC, so there must be models out there on how to do this.
An audience facet would be a good way to handle reading level as well, either by grade or age.
- Example: 0-1, 1-3, 9-10, etc.
- There is a tension between having too many optional facets and universality.
The facets need to transcend stickering, the current practice in most public libraries.
We need a reality check before getting to far down the road with proposed schedules for OSC– will it work in an actual library?
- We could upload a library’s MARC records into LT and try it there virtually before asking a library to use it.
- Two potential public libraries were listed as testing grounds.
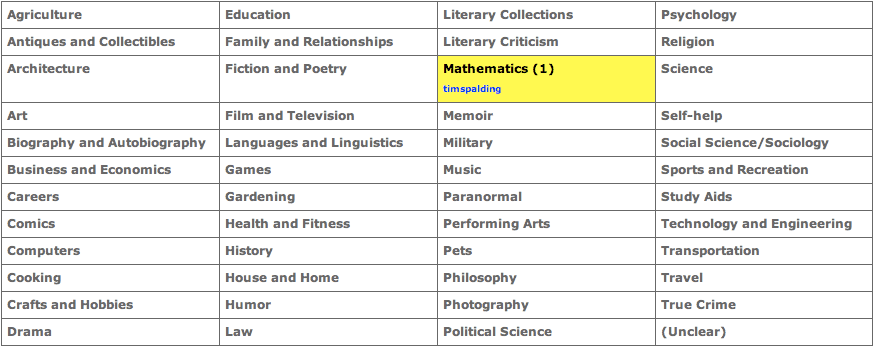
So far, the top levels testing on LibraryThing has provided the following results:
- 56641 acts of classification
- By 1000+ users
- On 22,000+ works
What are the biggest tags in LibraryThing, can we use those to determine the levels?
- They were looked at and evaluated, hence True Crime is a top level.
- This can’t really be done in an automated way.
What is the product plan for OSC?
- The data is open source & free.
- If people want to package services around the data (such as reclassifying books for you), then that is a possibility, but we do not see this developing for at least a year or so.
What does “shelf-ready” mean?
- A vendor puts on labels, dust jackets, tattle tape, creates catalog records for a public library.
- Different people at the meeting had differing levels of success with outsourcing their books to be made shelf-ready by vendors.
Is bleed over between categories in OSC a bug or a feature?
- Memoirs/Autobiographies was seen as a bug.
- Others such as Pets/ScienceAnimals were not seen that way.
Putting categories in an order may help people’s confusion of where to put things.
- This is called “flow” in bookstores.
- E.g. Cooking—Health—Sports or Biography—History—Poly Sci
Confusion arose over facets.
- You add and delete depending on the libraries needs.
- Huge collection? Use them all. Small and only need Science and Religion? Go ahead, the system is flexible.
The top level testing will stop and the levels will begin to be re-worked this week.
How should Art, Architecture, Design, and Photography be handled?
- After much discussion, the consensus was reached that Art, Architecture, and Design should be separate top level categories, but that Photography would go under Art.
The first test round has been closed. Visit the Open Shelves Classification group for details.
Meeting like this was great and very helpful in making OSC usable. Another meeting is planned in New York for early April–we’ll keep you posted!



 Laena M. McCarthy (user:
Laena M. McCarthy (user:  David Conners (user:
David Conners (user: 
