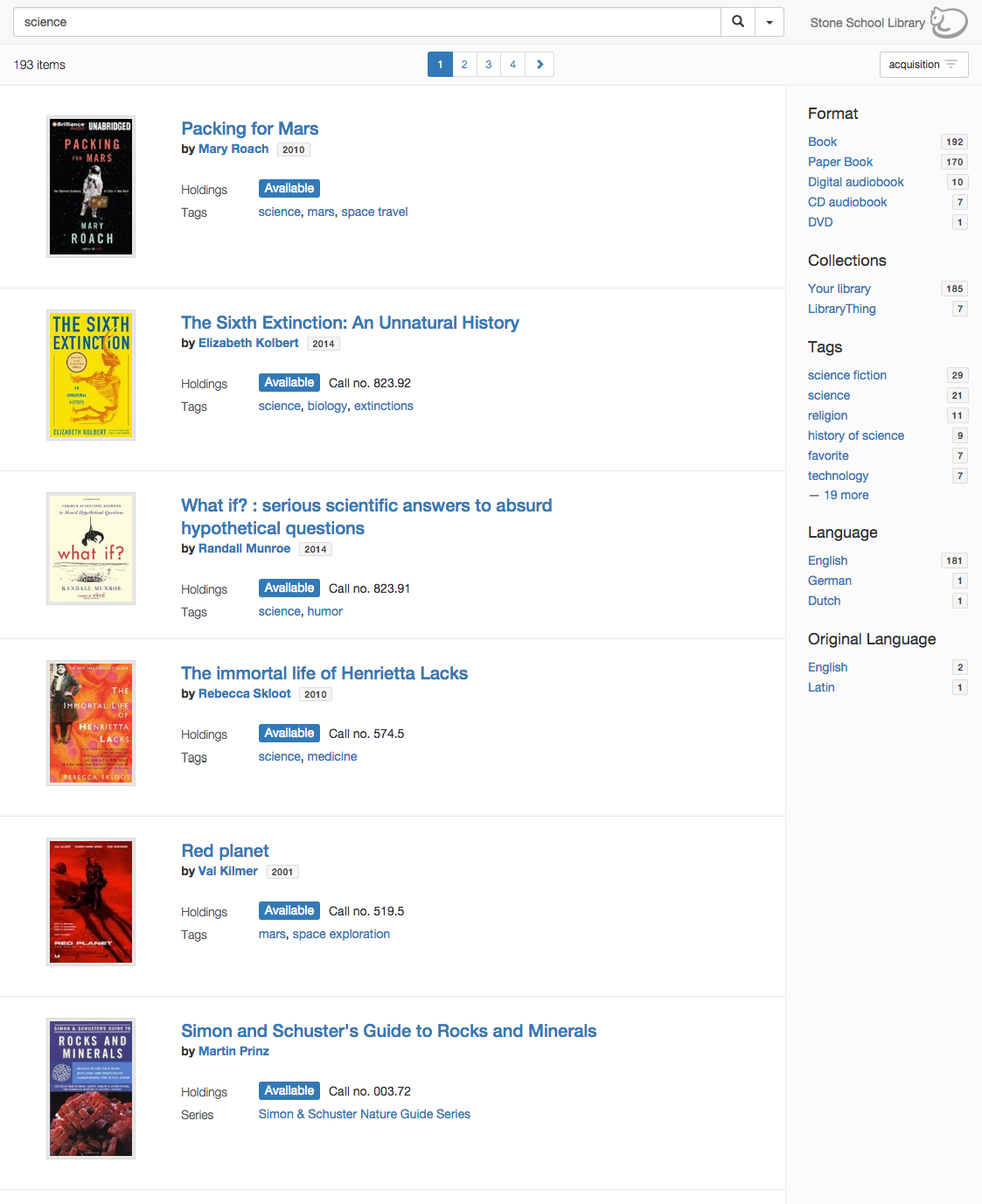
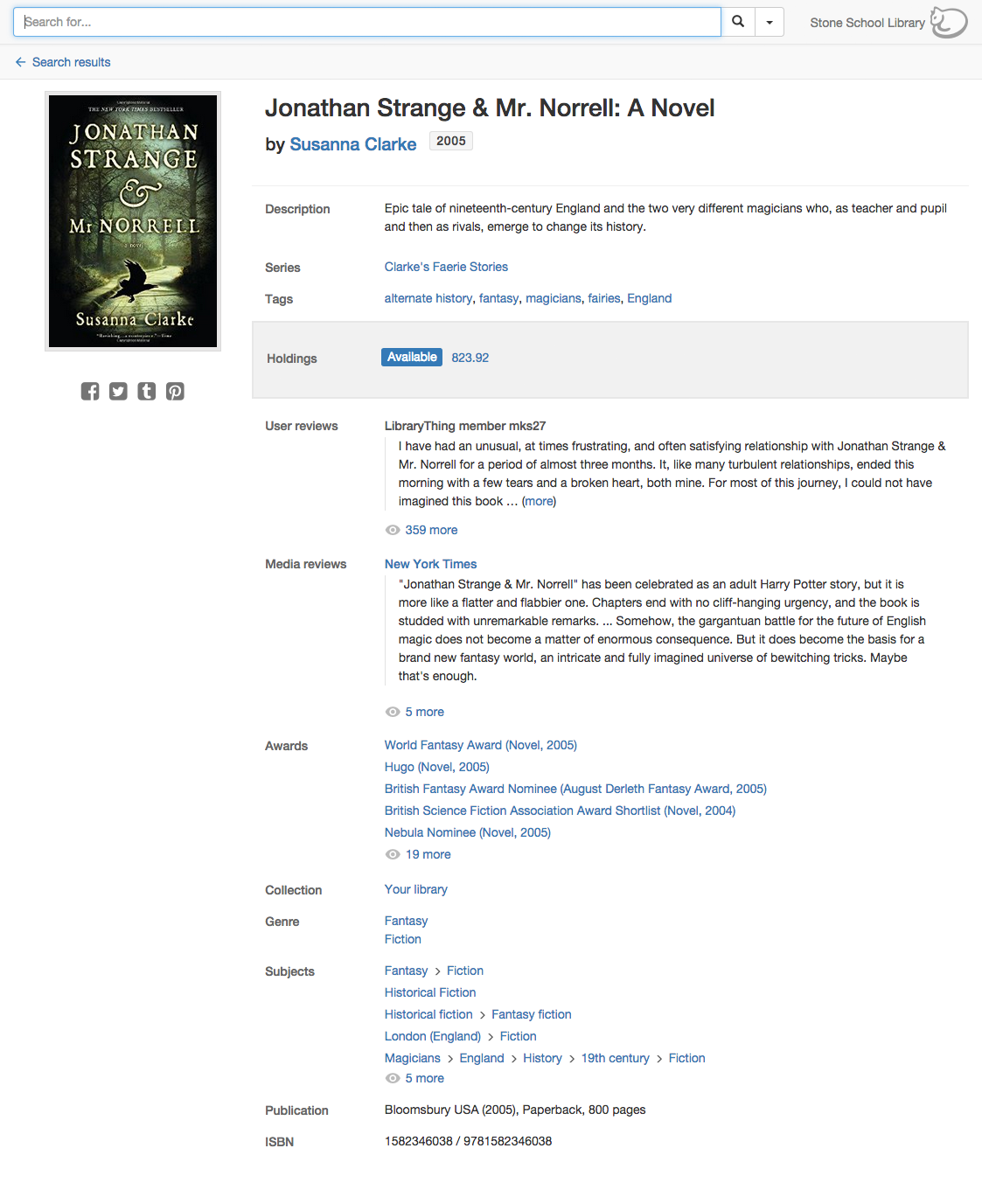
 We have added a new source to every member’s Add Books page: OverCat, LibraryThing’s new index of 32 million library records, assembled from libraries around the world, and the first step in a major upgrade of LibraryThing’s cataloging functions.
We have added a new source to every member’s Add Books page: OverCat, LibraryThing’s new index of 32 million library records, assembled from libraries around the world, and the first step in a major upgrade of LibraryThing’s cataloging functions.
Sources. OverCat was assembled from over 700 sources. The core consists of full datasets from the Library of Congress, Washington State, Boston College, Oregon State, and Talis Base (a collection of UK libraries).* To this we’ve added records from the hundreds of thousands of books members have searched for and added from the 690 libraries LibraryThing connects to.
The end result is arguably the second-largest searchable database of library records in existence, after OCLC.**
 How to use it. To use OverCat, go to your Add books page. OverCat has been added to everyone’s source list. (It can be removed but not yet reordered.)
How to use it. To use OverCat, go to your Add books page. OverCat has been added to everyone’s source list. (It can be removed but not yet reordered.)
High-quality results. To make it easier to find the edition you need, OverCat combines results into edition-level clusters, so you get one result per edition (rather than pages and pages of the same edition of the same book from different libraries). By default, it will give you what it guesses the best available record is for that edition, but you can select from any one of the alternate records if you want to.
OverCat isn’t everything. The Library of Congress data dump is not current–although it’s been supplemented with user searches. Our relevancy ranking isn’t as good as Amazon’s. (We could use your feedback to make it better.) But most users will find it a useful source, and many will find it the best one.
The Big Issue. OverCat is available to LibraryThing members in the course of normal site activity—cataloging small collections of books.*** It will not be available for external access, including by libraries. It is not a back door to OCLC data.
This will come as a disappointment to many, including us. We have long argued for library-data openness and against OCLC’s bid to privatize and monopolize library data. But we also made it clear to the libraries we search that their data will not be made available outside of the context of personal cataloging without their permission. This will not change, now or in the future.
We would love to open OverCat up, to make it OpenLibrary as we originally hoped it would be it, or like Amazon Web Services, but with free, high quality data. We believe data openness is critical to the survival of libraries in our increasingly free and open world. But we depend upon open search portals, and will never open up a library’s data against its wishes. Some of these libraries may want to open up their data, but some clearly do not, and almost everyone is afraid of OCLC and its new data policy.*** Either way, we will abide by libraries’ wishes.
For the 690 libraries we search little has changed. We will still send member searches to your systems, but fewer—reducing your load—and the requests may not come at the time of searching. As before, found records will be stored on LibraryThing systems, but can now be used by more than one user and will appear in OverCat searches. Bulk or non-personal access will not be possible.
Thanks. OverCat has been a long-term project of Casey Durfee. The Board for Extreme Thing Advances helped us nail down bugs and decide on the name.
The future. LibraryThing’s greatest strength is its cataloging, but we don’t want to rest on that. There are a lot of improvements we can do now that we have a flexible, scaleable structure and repository for our data. OverCat is the first step here.
Come talk about your suggestions, and OverCat generally, on Talk here.
*Some OpenLibrary data was omitted for being mostly duplicative or of insufficient quality.
**For background on the OCLC issue, see here. We will also honor requests to remove libraries’ data from OverCat, excepting those libraries (like the LC), whose records are public by both law and public dumps.
There are larger collections. Harvard, for example, is said to have contributed 81 million records to OCLC, but most can’t have been book records, as the volume-count of Harvard is less than that of the Library of Congress, which we include.
We could make part of the data free, and part closed. But since the free data comes from OpenLibrary it would be duplicative of their efforts. We may explore this avenue in the future, as our primary complaint against OpenLibrary is the lack of exportable library-data formats.
***Exports of your library are included, obviously, but no larger dumps. “Personal” includes some small institutions, like church libraries, clubs and so forth.
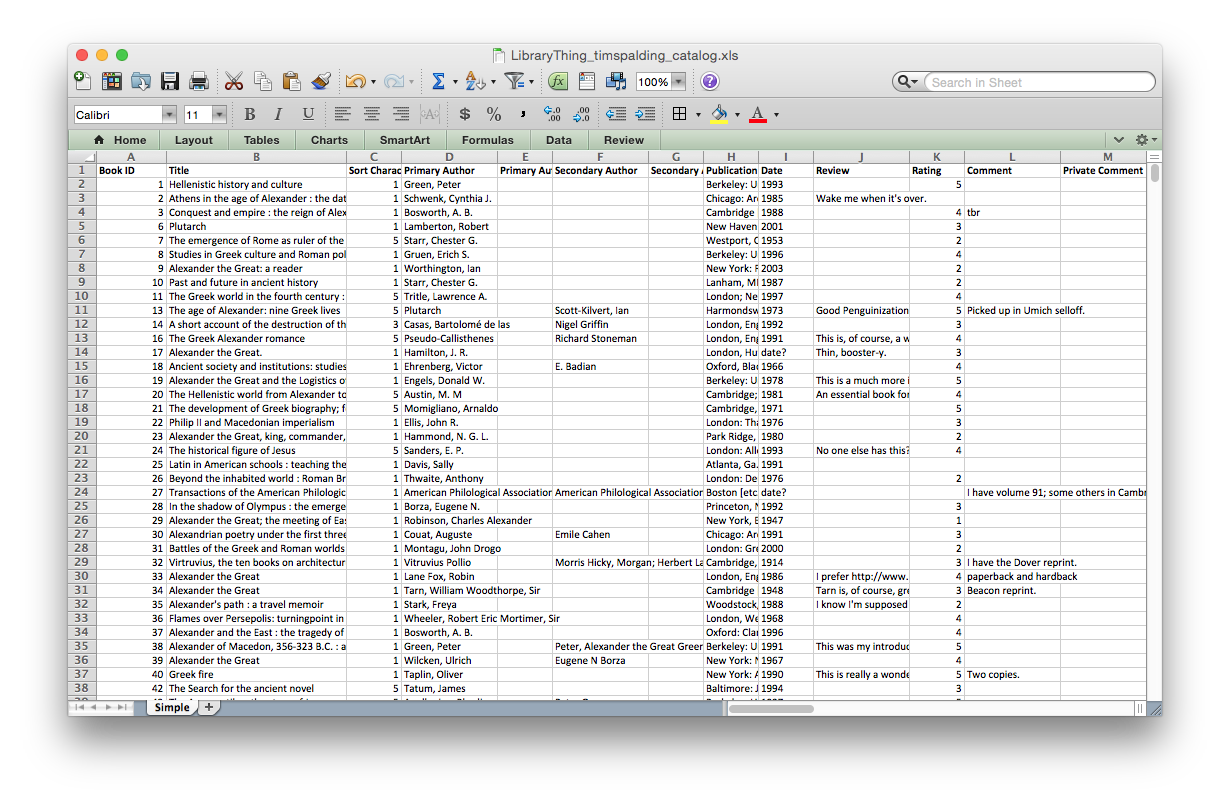

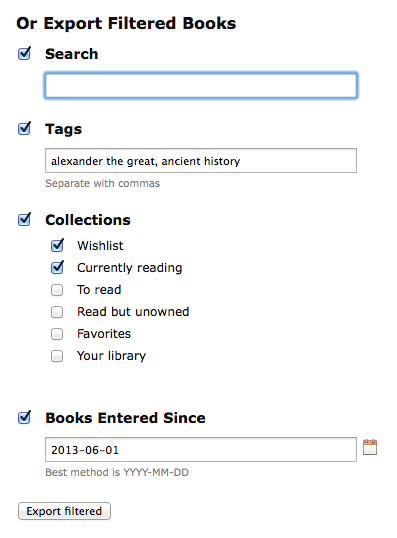
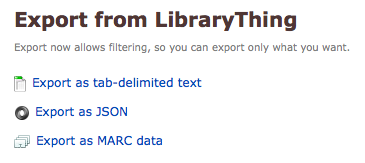


 I’ve added a tab-delimited export, for use in Microsoft Excel and elsewhere. Go to the
I’ve added a tab-delimited export, for use in Microsoft Excel and elsewhere. Go to the 











 We’re pleased to introduce Ammar Abu-Yasein (member
We’re pleased to introduce Ammar Abu-Yasein (member 
 As a security precaution, we are requiring ALL members to change their passwords, here:
As a security precaution, we are requiring ALL members to change their passwords, here:  Once you’ve uploaded your file, you’ll see a breakdown of the books in the file, displaying the total number of books, books already in your library, books without ISBNs, and the number of valid ISBNs.
Once you’ve uploaded your file, you’ll see a breakdown of the books in the file, displaying the total number of books, books already in your library, books without ISBNs, and the number of valid ISBNs. If you sync, you’ll see options depending on the differences between your Goodreads books and your LibraryThing catalog.
If you sync, you’ll see options depending on the differences between your Goodreads books and your LibraryThing catalog.



 Introducing our new series: “29 Things You Didn’t Know you Could Do with LibraryThing” our attempt to introduce cheesy “style magazine” graphics and arbitrary numbers to the LibraryThing blog!*
Introducing our new series: “29 Things You Didn’t Know you Could Do with LibraryThing” our attempt to introduce cheesy “style magazine” graphics and arbitrary numbers to the LibraryThing blog!*
 We just hired Casey Durfee (
We just hired Casey Durfee (